An unexpected pandemic side hustle, the studio produced its first independent AI research paper, accepted into ICCV ’21 after double blind review. Begun as open-ended art exploration, we hoped our model, Sensorium, might be of interest to the broader research community and crafted it into a paper.
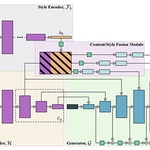
A domain translation model building upon SPADE and StyleGAN, we define ‘content’ as conditioning information extracted by off-the-shelf pre-trained models (depth, pose, segmentation, etc) and achieve high quality synthesis of complex, unaligned scenes. We are gratified in how these ideas have been carried forward by ControlNet.
Truly a collaboration, Cooper Nederhood and I led the research with vital contributions from Nick Kolkin, and valuable support from Deqing Fu. I deeply enjoyed the process of making this paper and learned a lot about the dance of computer vision publishing. In some ways, not so different from the machinations of presenting art. In other ways, universes apart.
[ABSTRACT]
Multi-modal domain translation typically refers to synthesizing a novel image that inherits certain localized attributes from a 'content' image (e.g. layout, semantics, or geometry) and inherits everything else (e.g. texture, lighting, sometimes even semantics) from a 'style' image. The dominant approahc to this task is attempting to learn disentangled 'content' and 'style' representations from scratch. However, this is not only challenging, but ill-posed, as what users wish to preserve during translation varies depending on their goals. Motivated by this inherent ambiguity, we define 'content' based on conditioning information extracted by off-the-shelf pre-trained models. We then train our style extractor and image decoder with an easy to optimize set of reconstruction objectives. The wide variety of high-quality pre-trained models available and simple training procedure makes our approach striaghtforward to apply across numerous domains and definitions of 'content'. Additionally it offers intuitive control over which aspects of 'content' are preserved across domains. We evaluate our method on traditional, well-aligned, datasets such as CelebA-HQ, and propose two novel datasets for evaluation on more complex scenes: ClassicTV and FFHQ-Wild. Our approach, Sensorium, enables higher quality domain translation for more complex scenes.